An enterprise AI stack should not fall apart every time a model provider ships a new release. Yet that is exactly what happens when the application is wired too tightly to one API, one response format, or one style of tool calling.
The result is usually not dramatic failure. It is worse than that. The system still runs, but the output no longer fits the rest of the pipeline.
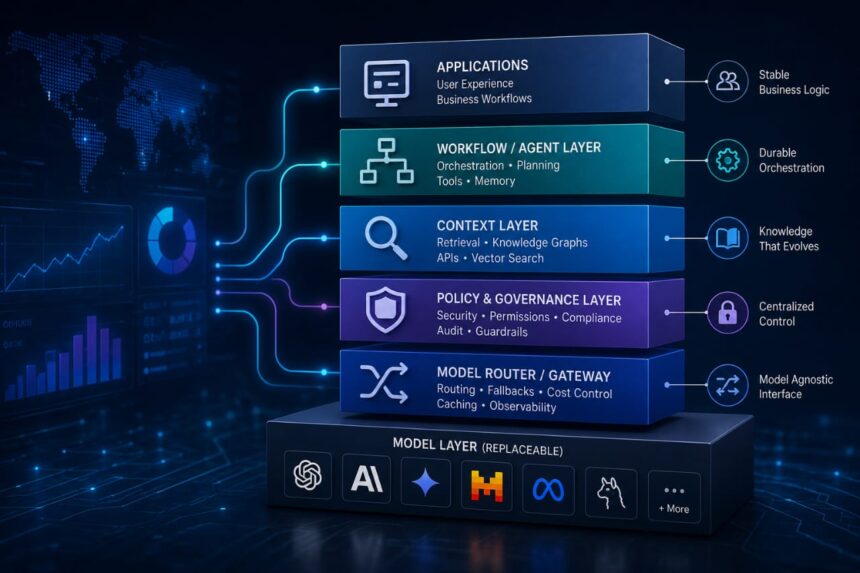
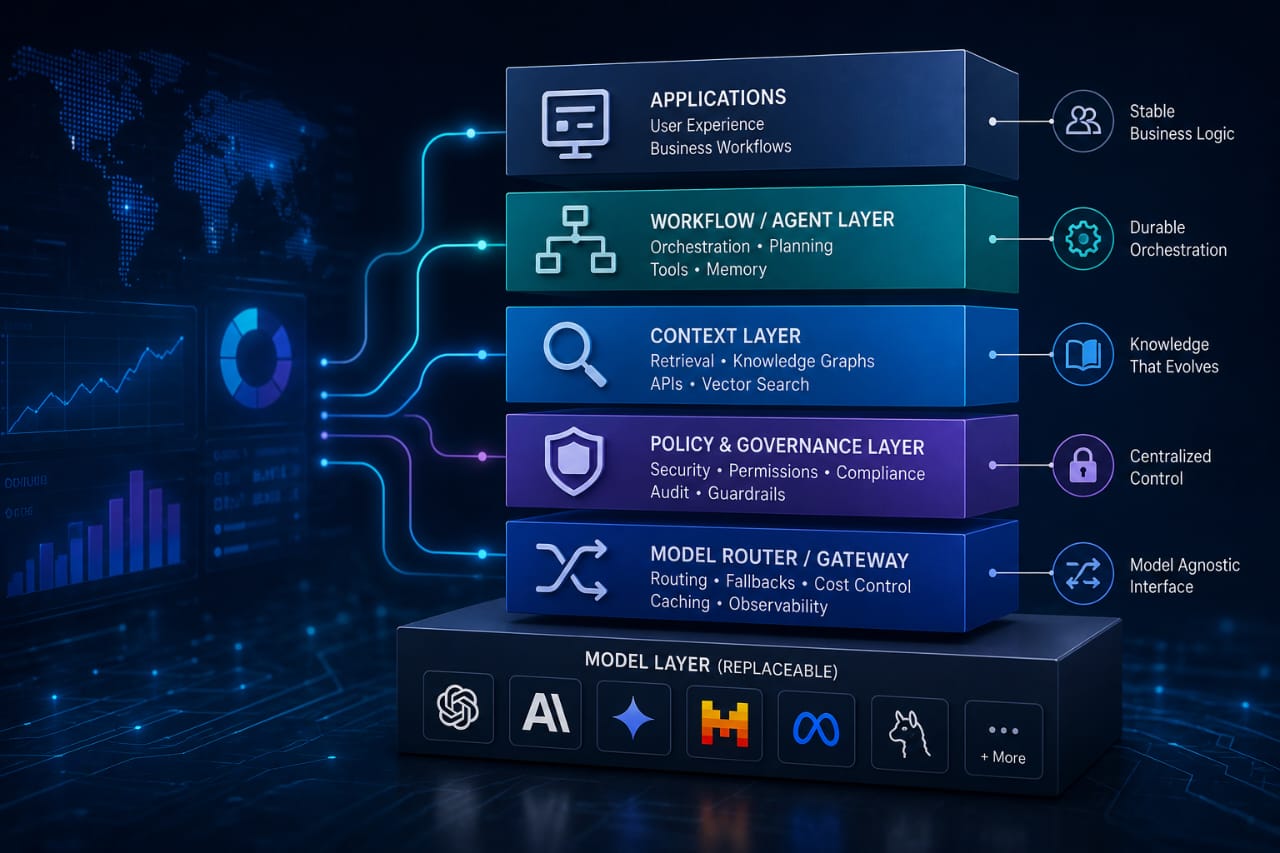
That is the part many early deployments miss. The model is only one layer in an enterprise AI stack, and it should be treated like a replaceable component, not the center of the design. The durable parts are the retrieval layer, the workflow layer, the policy layer, the logging path, and the evaluation setup that tells you when something has shifted.
How an Enterprise AI Stack Breaks After a Model Swap
In early deployments, the architecture often looks simple:
Application → Single Model API → User
That is fine for a demo. It is fragile in production.
A real failure pattern looks like this. An internal document assistant is built to extract fields from long policy pages and return structured JSON. For months, the output shape stays stable enough that the downstream parser does its job without drama. Then the provider changes model behavior in a new release. The answer still looks good to a human, but a key field now moves from a string to a nested object, and the parser starts dropping records. Nobody notices at first because the text “reads well.” The workflow only starts leaking when the missing field affects a later approval step.
That kind of problem is common because model upgrades change behavior in ways that are difficult to spot by eye. The stack did not fail at the model layer alone. It failed because too much logic was glued to model output.
The safer shape is more layered:
Application
↓
Workflow / Agent Layer
↓
Policy + Routing Layer
↓
Multiple Models
That structure gives you room to replace one model without rebuilding the rest of the system. It also gives you a place to route sensitive requests differently from low-risk ones. One system can serve a customer-facing assistant, a document extraction flow, and an internal search tool without forcing all three to use the same model behavior.
How an Enterprise AI Stack Stays Flexible
The first rule is to keep business logic out of prompts. Prompts are useful, but they are not a safe place for long-lived rules. A pricing rule, an access rule, or a compliance rule should live in code, policy checks, or a workflow engine that can be tested directly.
The second is to keep orchestration separate from inference. If a model gets replaced, the workflow should still know how to fetch context, call a tool, retry a failure, and store the result. That is where systems like LangGraph and Temporal are useful, since they let execution stay durable even when the model behind it changes.
The third rule is to route by task, not by habit. A product support summary does not need the same model as a contract review. A short extraction job does not need the same latency budget as a long reasoning flow. If every request goes through the same provider because that was the first one that worked, the stack becomes expensive and brittle at the same time.
That is usually where an internal model gateway earns its keep. It can apply retries, rate limits, fallback logic, and logging in one place. It can also route private workloads to a local model and keep public-facing work on a managed provider. The application does not need to know which model answered. It only needs a stable interface.
For teams that are planning against vendor lock-in, the Model Context Protocol is worth watching. It creates a more consistent way for models to access tools and external systems. That is useful, but it also demands tighter controls around permissions, logging, and execution boundaries.
Retrieval is doing more of the heavy lifting
Most enterprise systems do not need the model to memorize everything. They need the model to find the right material quickly and use it well. That is a retrieval problem first and a language problem second.
In practice, a strong enterprise AI stack usually looks like this:
Knowledge Base → Retrieval → Context Injection → Model
This is a better setup because knowledge changes often. Policies get updated. Product docs drift. Internal process notes go stale. If all of that lives inside prompts, you end up rewriting prompts constantly. If it sits in a retrieval layer, the system can fetch fresh context without changing the rest of the flow.
A useful retrieval path usually combines keyword search, semantic search, and reranking. One search method alone tends to miss things. Semantic search can surface relevant passages, but exact terms still matter in legal, financial, and operational material. Hybrid retrieval gives a better shot at finding the right section, especially when the source documents are messy.
Resources such as Pinecone’s retrieval guides and OpenAI’s retrieval documentation are useful starting points for people building these pipelines from scratch.
There is a quiet lesson here. A model upgrade can improve reasoning and still leave retrieval quality untouched. That means the larger system may still perform badly even after the “better” model goes live. The stack needs evaluation at the retrieval layer, not just at the model layer.
Evaluation Needs to Sit Beside the Stack, Not Behind It
If a model swap is done without evaluation, the organization is essentially guessing. That sounds harsh, but it is common. A newer model is released. It benchmarks well. It feels smarter in a few test prompts. Then production users start seeing slightly different outputs that are harder to parse, harder to rank, or harder to trust.
Good evaluation catches that before launch. It should compare model versions on real tasks, not just generic benchmarks. A support classifier should be tested against historical tickets. A document extraction flow should be replayed against known inputs. A summarizer should be checked for omissions in exact source material, not only for style.
That is where tools such as LangSmith and Arize AI are useful, because they help track regressions, trace failures, and compare outputs over time. The point is not to admire metrics. The point is to know whether a swap changed something the business relies on.
Good evaluation also needs a shadow path. Run the new model beside the old one for a period of time. Compare outputs quietly. Look for shape changes, missing fields, tool-call failures, and latency spikes. The odd little break is usually the one that turns into a production headache later.
That is not glamorous work. It saves money anyway.
How to Build for Model Changes Without Rebuilding Everything
There is a practical way to approach this.
Start by defining a stable contract between the application and the AI layer. The app should ask for an outcome, not a specific model behavior. Use schemas for structured outputs. Validate them before passing results downstream. Keep model responses inside an adapter so the rest of the code never depends on one provider’s quirks.
Next, separate sensitive work from general work. Private content, regulated data, and internal workflows may need local inference or tighter controls than a public assistant. That is where policy checks and execution boundaries belong. Do not bury those decisions inside a prompt.
Then build the retrieval layer as a first-class system. Track source freshness. Track failed lookups. Track which content is being pulled most often. If retrieval goes wrong, the model is often blamed first, even when the real issue is stale content or poor chunking.
After that, add model routing. Route by task, latency, cost, and data sensitivity. Let the system choose the model instead of forcing every request through the same endpoint. That keeps options open when pricing shifts or a provider changes behavior.
Finally, keep a regression suite alive. Test real inputs. Track real failures. Re-run them every time a model, embedding model, prompt template, or retrieval index changes. A stack that survives model changes is usually a stack that has learned to expect them.
That is the point. Stability does not come from betting on a model that never changes. It comes from designing the rest of the system so change is not a crisis every time it arrives.



