
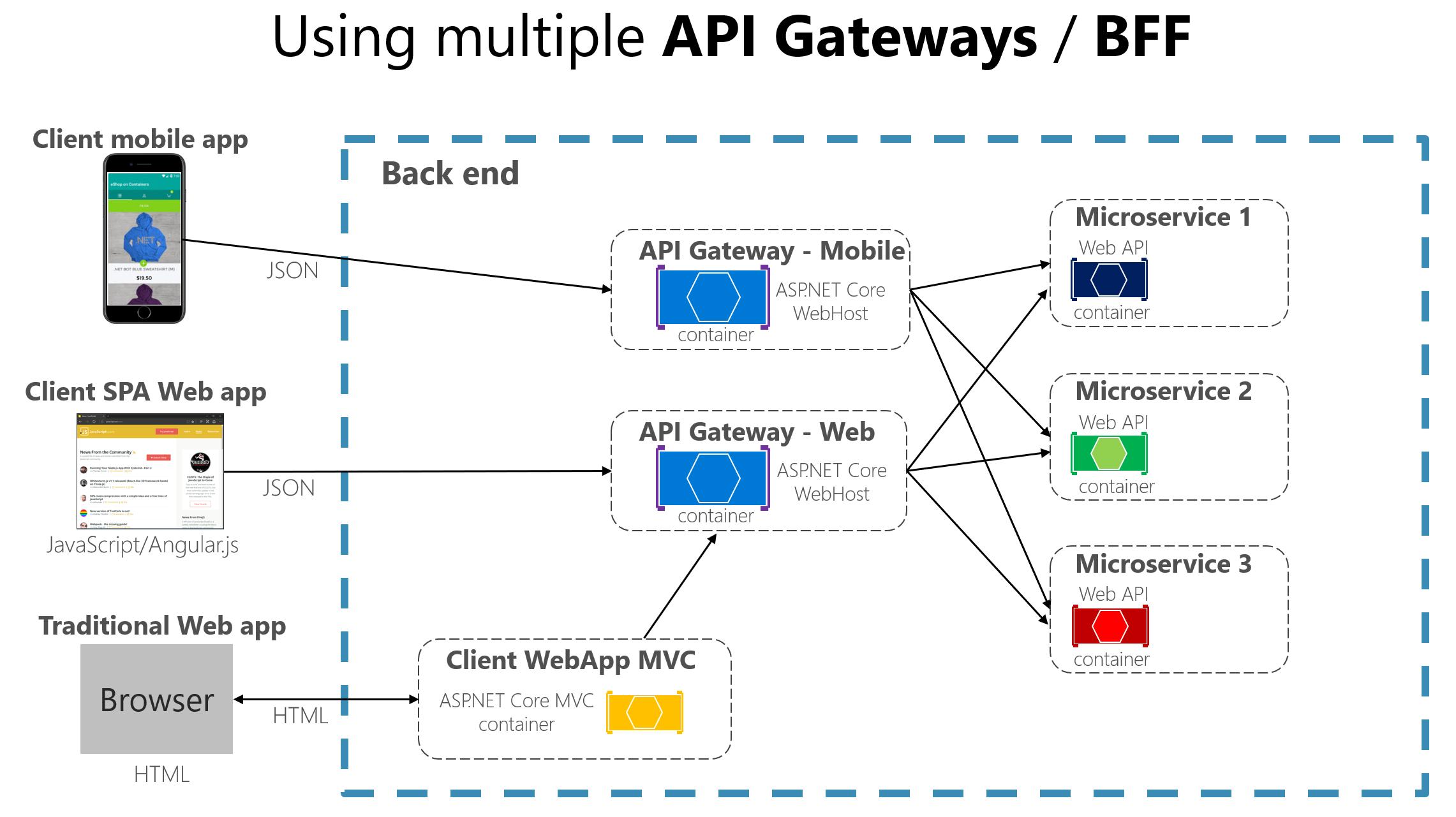
Secure API design patterns start before the first endpoint is shipped. The shape of the API, the authentication model, the way objects are exposed, and the rules around query execution all create security outcomes long before anyone writes a pentest report. That is especially true when teams run both REST and GraphQL side by side, because the same backend can be exposed through two very different surfaces.
REST usually gives you many small entry points with explicit resources. GraphQL gives you one endpoint with a flexible execution layer. Both can be secure, but the controls are not identical. The OWASP API Security Top 10 2023 is still the best place to anchor the risk model: broken object-level authorization, broken authentication, excessive data exposure, and unsafe business logic are not abstract concerns. They are the things that show up in real systems when the design is too trusting or too generous with data.
What follows is the practical version: how to design APIs so the security model is built into the shape of the interface, not bolted on after the fact.
Secure API Design Patterns for REST
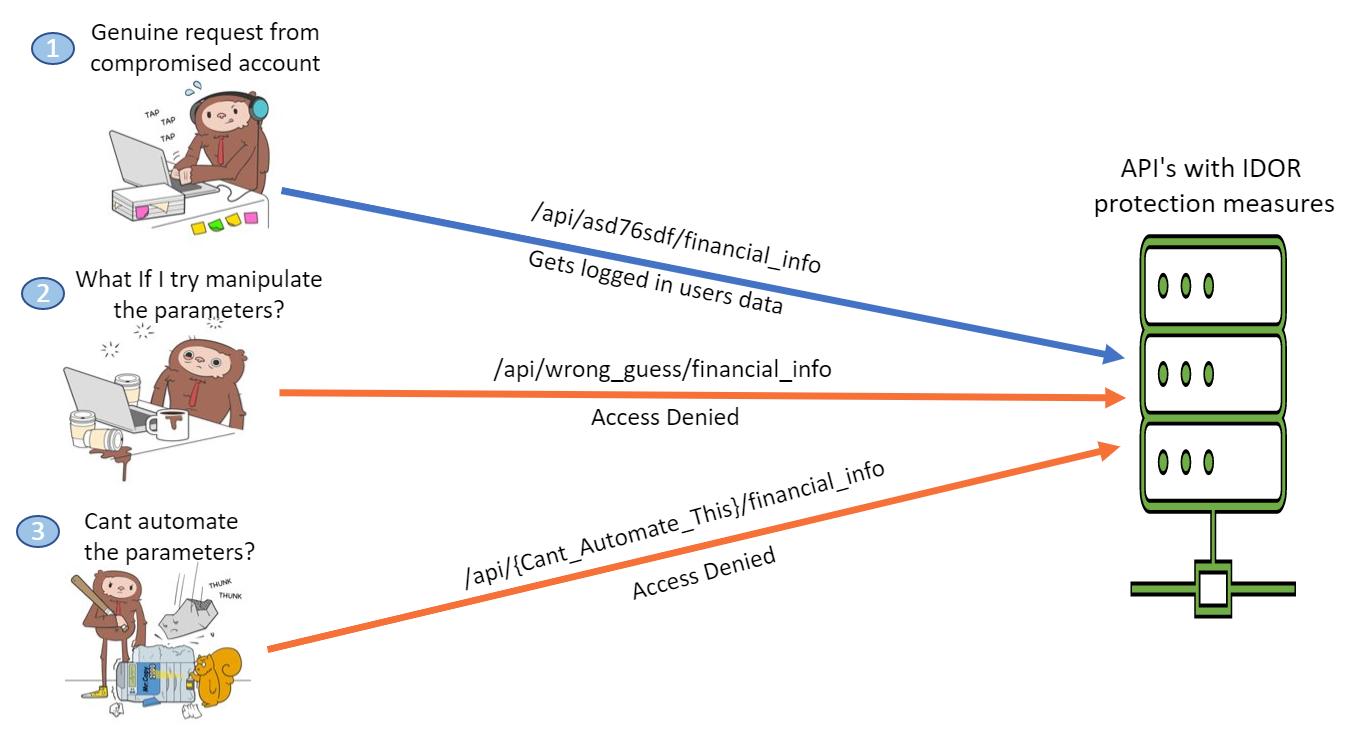
REST security works best when the resource model is strict and the authorization logic follows the object, not the route. The classic failure is an IDOR-style bug, where a caller changes an identifier in a path or body and gets someone else’s record. OWASP’s IDOR Prevention Cheat Sheet is blunt on this point: object access checks have to happen on every request that touches a data source. That means checking ownership, tenancy, role, or policy at the server, not relying on the client to behave.
In practice, the safest REST pattern is “resource first, policy second.” The API describes the resource clearly, but every access path still passes through a policy layer. When you expose /users/{id} or /orders/{id}, the handler should never assume the identifier is legitimate just because the request is authenticated. A token proves identity. It does not prove entitlement to that specific object.
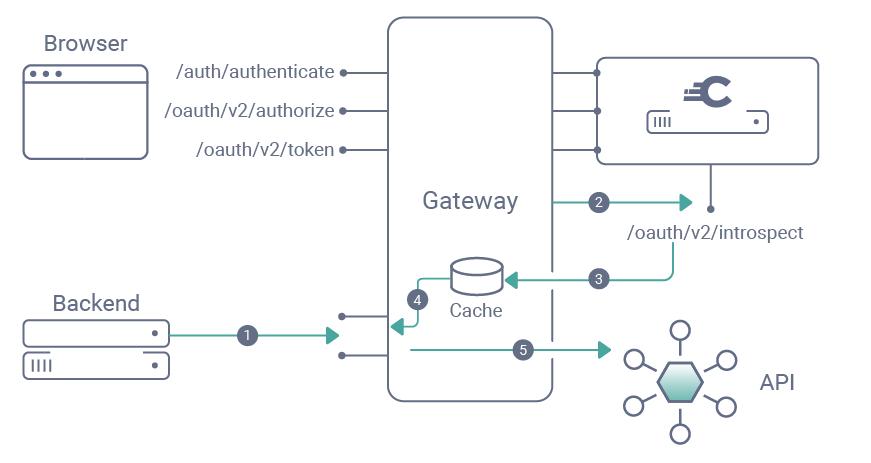
Transport security is the easy part, but it still needs to be explicit. The OWASP REST Security Cheat Sheet recommends HTTPS only, and that remains the baseline. For higher-trust APIs, mutual TLS can be a sensible addition, especially between services or for privileged administrative interfaces. The point is not ceremony. It is to make interception, replay, and credential theft harder in the layers where the request is still in motion.
Authentication design deserves the same discipline. For OAuth-based APIs, the current best current practice is RFC 9700, which updates and extends earlier OAuth security guidance. In many modern systems, the safer default is short-lived access tokens with narrow scopes, paired with refresh handling that is carefully bounded. If you use JWTs, the token format itself is not the security model. RFC 8725 exists because JWT deployment has a long history of validation mistakes: algorithm confusion, missing audience checks, weak claim validation, and treating a token as trustworthy without checking its context. A token is only useful when validation rules are strict and consistent.
OpenAPI helps here because it lets you describe security requirements and scope expectations directly in the contract. The OpenAPI 3.1 specification allows security schemes to be defined centrally and overridden per operation. That makes the contract a useful guardrail for reviews, automated tests, and gateway policy generation. It does not enforce behavior by itself, but it gives teams a shared source of truth for how the API is supposed to be protected.
Another pattern worth keeping is response minimization. REST handlers should return the smallest useful object, not the full database row with a few fields hidden “just in case.” Excessive data exposure usually happens when serialization is too broad or when an object model is exposed directly. Good REST design maps internal models to explicit response shapes. That extra mapping step is not overhead; it is where you prevent accidental disclosure.
Secure API Design Patterns for GraphQL
GraphQL changes the attack surface because callers control the shape of the response. That flexibility is useful, but it also means the server has to defend against expensive execution paths, over-broad field access, and resolver-level authorization mistakes. The GraphQL project’s own security guidance and the OWASP GraphQL Cheat Sheet both point to the same core controls: input validation, query limits, access checks, and disabling risky defaults.
The central pattern in GraphQL is to secure every resolver. A common mistake is to validate the request once at the top of the stack and then assume all nested fields are safe. That does not hold up in practice. A query can legally ask for a field that should only be visible to a subset of users, or it can traverse into related objects that belong to a different tenant. Authorization has to exist at resolver boundaries, because that is where data is actually assembled.
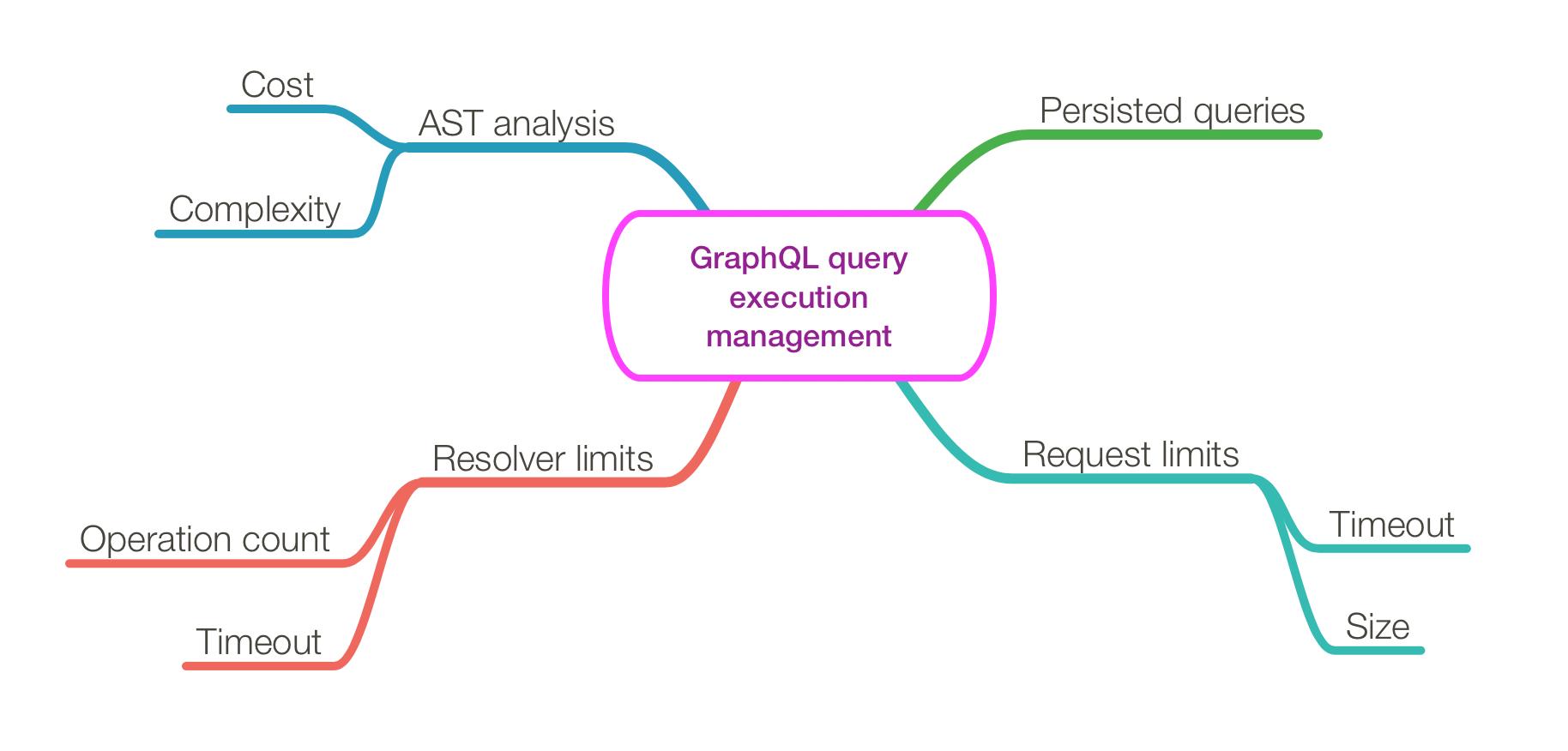
Query complexity controls are not optional. The GraphQL docs recommend practical defenses such as timeouts and maximum query depth, and the OWASP cheat sheet calls out expensive queries as a denial-of-service risk. A query can be small in byte size and still be expensive if it walks deep object graphs or fans out into many resolvers.
Depth limits, cost analysis, and persisted queries are useful because they reduce the server’s exposure to arbitrary client-shaped workloads. In a production setting, persisted or allowlisted operations are often the most predictable option because they limit the server to known query shapes.
Introspection is another place where teams get too relaxed. The GraphQL specification supports introspection because tooling depends on it, but production exposure should be a deliberate decision. If you leave introspection open without any guardrails, you make schema discovery easier for legitimate tooling and for attackers. The safer pattern is to allow it where it helps development, then restrict it in production or require strong authentication before it reveals useful structure.
Error handling needs care as well. GraphQL often returns partial success, with data and errors together. That is a feature, not a flaw, but it changes how you think about logging and client behavior. Error messages should be specific enough for operators, but not so specific that they hand out schema details, stack traces, or internal identifiers. The OWASP testing guidance for GraphQL also warns against relying on blocklists alone, because aliases and nested requests can bypass simplistic checks.
The transport layer still counts. The GraphQL project’s GraphQL over HTTP draft and the official serving over HTTP guidance describe HTTP as the common transport, while subscriptions often use WebSockets or server-sent events. That means the same old controls still apply: TLS, session handling, proxy limits, and careful logging. GraphQL does not replace transport security. It sits on top of it.
Common Failure Modes Teams Keep Repeating
The repeat offenders are familiar. Teams trust the client to enforce permissions. They expose internal fields because the schema was generated from the database. They accept arbitrary query shapes and only discover the cost problem after traffic rises. They use JWTs but never validate audience or token type properly. They publish GraphQL introspection publicly and then wonder why the schema shows up in crawler logs. None of these are peculiar failures. They come from optimistic assumptions.
The real constraint is organizational, not technical. REST and GraphQL both reward teams that keep the security policy close to the execution path. That means policy checks in handlers and resolvers, schema reviews that include security, and contract tests that verify negative cases, not just happy-path responses. It also means measuring what the API actually does in production. Rate limits, resolver timings, object access patterns, and error volume tell you a lot more than a design doc does after launch.
What to Check Before You Ship
Before shipping a REST API, check whether every object lookup has an ownership or policy check, whether the response shape excludes internal fields, whether token scopes match real operations, and whether the OpenAPI contract reflects the actual security scheme. Before shipping GraphQL, check whether resolvers enforce access control independently, whether query depth and cost are capped, whether introspection is intentionally exposed, and whether allowlisted or persisted queries are available for sensitive paths.
Also check the boring things. Review logs for secrets, confirm that HTTPS is enforced everywhere, verify token expiry and revocation behavior, and test what happens when a caller asks for more data than they should see.


