

Sudden drops in indexed pages can feel abrupt, but in most cases, they follow a pattern that can be traced and resolved. Sudden deindexing issues rarely come out of nowhere; they are usually the result of technical changes, shifts in how search engines evaluate content, or a gradual decline in page-level signals that finally crosses a threshold.
What complicates things is that not every drop in indexed pages reflects an actual removal. Reporting delays, classification changes, and crawl prioritization can all create the appearance of loss without a true disappearance from search results. Sorting out that distinction early prevents wasted effort.
Confirming the Scope of Sudden Deindexing Issues
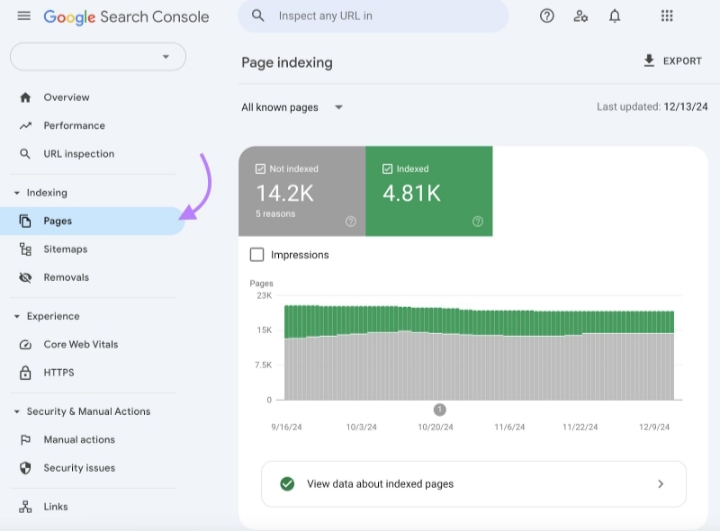
The first step is to establish whether pages are genuinely removed or simply reclassified. A basic site: query can reveal whether URLs still exist in the index, but this should be paired with inspection inside Google Search Console. The Pages report provides a clearer breakdown of how URLs are treated, including categories such as “Crawled, currently not indexed” or “Discovered, currently not indexed.”
These classifications often get misinterpreted. A page that moves into “Crawled, currently not indexed” has not been banned or penalized. It has simply failed to meet the threshold required to remain indexed at that moment. That distinction changes the entire recovery approach.
Look for timing patterns. If the shift aligns with a deployment, the cause is likely technical. Does it aligns with a known update, the cause leans toward content evaluation. If there is no clear trigger, segmentation becomes the next step.
A single overlooked detail can explain a large drop.
Technical Triggers that Quietly Remove Pages
Technical misconfigurations remain the most direct cause of sudden deindexing issues. They tend to affect large portions of a site at once and can be introduced through routine updates.
A misplaced directive or header can propagate across templates and remove entire sections from the index within hours.
The most common patterns show up in three areas.
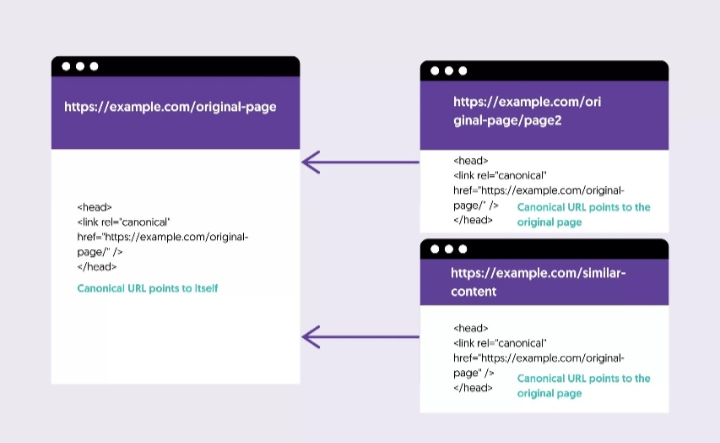
- First, unintended
noindexdirectives, either in meta tags or HTTP headers, often appear when staging configurations are pushed live. - Second,
robots.txtrules can block crawling paths that were previously open. - Third, canonical tags can redirect indexing signals away from the intended page.
Server behavior is just as important. Persistent 5xx errors, intermittent downtime, or aggressive firewall rules can prevent search engine crawlers from accessing content reliably. In some cases, content delivery networks or security layers misidentify crawlers as threats, leading to silent blocking.
A quick header check using a command-line request can reveal issues that are not visible in the browser. Pay attention to response codes, redirect chains, and any indexing directives returned in headers.
When technical causes are responsible, fixes tend to produce faster recovery once corrected and recrawled.
Content Evaluation and Index Pruning
Not all sudden deindexing issues originate from technical faults. In recent cycles, search engines have become more selective about what remains indexed, especially at scale. Pages that offer little differentiation, outdated information, or minimal engagement are increasingly moved out of the index.
This is often visible in clusters rather than isolated pages.
Older articles, lightly edited rewrites, and content that mirrors existing sources without adding new perspective are typical candidates. The shift does not necessarily reduce traffic if those pages were not contributing meaningfully in the first place.
Data from performance reports helps clarify this. Pages that show zero impressions over extended periods are often the first to be excluded. When grouped together, they reveal a pattern tied to content depth, structure, or relevance.
There is a tendency to try to restore every removed page. That approach usually leads to diminishing returns. A more effective method is to identify which pages deserve to remain and focus on strengthening those. Some pages are better merged than revived.
How Internal Structure Influences Indexing
Internal linking plays a larger role than it appears on the surface. Pages that are weakly connected or completely orphaned often struggle to remain indexed, regardless of their standalone quality. Search engines rely on internal signals to determine importance and context.
Sites with fragmented structures tend to see uneven indexing behavior.
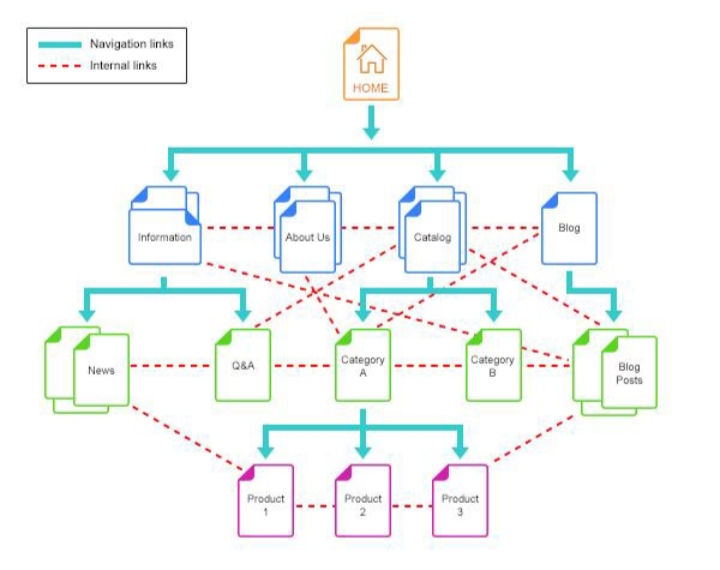
Clusters that are tightly linked and consistently updated remain stable, while isolated pages drop out over time. This becomes more visible when analyzing crawl paths using tools like Screaming Frog SEO Spider, which can surface orphaned URLs and weak link distribution.
Strengthening internal pathways does not require large-scale redesign. In many cases, it involves revisiting key pages, adding contextual links, and ensuring that important content is reachable within a few clicks from primary sections. Structure often determines visibility.
Step-by-Step Process to Debug Sudden Deindexing Issues
The investigation works best when approached in sequence rather than jumping between assumptions.
Start by confirming index presence using search queries and inspection tools. Then review indexing reports inside Search Console, focusing on changes in classification rather than raw counts.
Next, segment affected URLs. Group them by type, age, and performance. This usually reveals whether the issue is isolated to a specific section or spread across the site. Follow this with a technical audit that checks directives, response codes, and crawl accessibility.
Once technical factors are ruled out, shift attention to content. Evaluate whether affected pages provide unique value, remain current, and align with user intent. Cross-reference this with performance data to identify which pages had measurable visibility before removal.
Then assess internal linking. Identify pages that lack inbound links or sit outside established content clusters. Reinforce connections where needed, particularly for pages that are intended to rank.
Finally, update and resubmit selectively. Refresh content where improvements are justified, update sitemaps, and request indexing for priority pages rather than the entire set. This signals intent without overwhelming crawl resources.
Each step builds on the previous one.
Recovery Patterns and Realistic Timelines
Recovery from sudden deindexing issues does not follow a fixed timeline.
Technical corrections can lead to visible changes within days once pages are recrawled. Content-related adjustments take longer, as they depend on reassessment cycles.
Submitting updated pages through URL inspection and recrawl requests can accelerate the process for key URLs, but large-scale recovery relies on consistent signals over time. Improvements in structure, relevance, and engagement tend to compound rather than produce immediate results.
It is also common for only a portion of removed pages to return. In many cases, the index stabilizes around a smaller, stronger set of URLs. This is not a failure of recovery but an indication that the site has been recalibrated.
Building Resilience Against Future Drops
Preventing future occurrences of deindexing issues comes down to maintaining consistency across technical and content layers. Regular audits help catch directive changes before they propagate. Monitoring indexing reports highlights shifts early, before they scale.
Content strategies should focus on depth and clarity rather than volume. Pages that serve a clear purpose, provide updated information, and integrate into a broader structure are less likely to be removed. Internal linking should be treated as part of content development, not an afterthought.
Over time, these practices reduce volatility and create a more predictable indexing pattern. The goal is not to keep every page indexed, but to ensure that the right pages remain visible. That distinction shapes long-term performance.



